
Managing Hyperscale objects
Introduction
After registering a Hyperscale Orchestrator, DCT will begin to ingest all relevant data discovered on that Hyperscale instance. This data, in turn, becomes modeled in the DCT world with APIs and a UI to (and manage to a limited extent). Currently, a lot of this data can be navigated to and viewed from the main overview details page of a Hyperscale Orchestrator.
Hyperscale executions
A view of all current and past Hyperscale job executions present on a particular Hyperscale Orchestrator can be found under the Job Executions tab. The View link will display additional information, especially for in-progress or failed executions.
Hyperscale jobs
A view of all Hyperscale jobs discovered on a Hyperscale Orchestrator can be found under the Associated Jobs tab.
The View link will take you to the Compliance Jobs details page where more information about the job can be found.
Hyperscale jobs are not separate entities in DCT, but rather are combined with standard Compliance jobs. Hence, this Hyperscale job details page can be navigated to from Compliance -> Compliance Jobs. There is a type attribute (Hyperscale or standard) which helps differentiate between the different types.
Configuration and dataset details can be edited directly in the job’s Overview page.
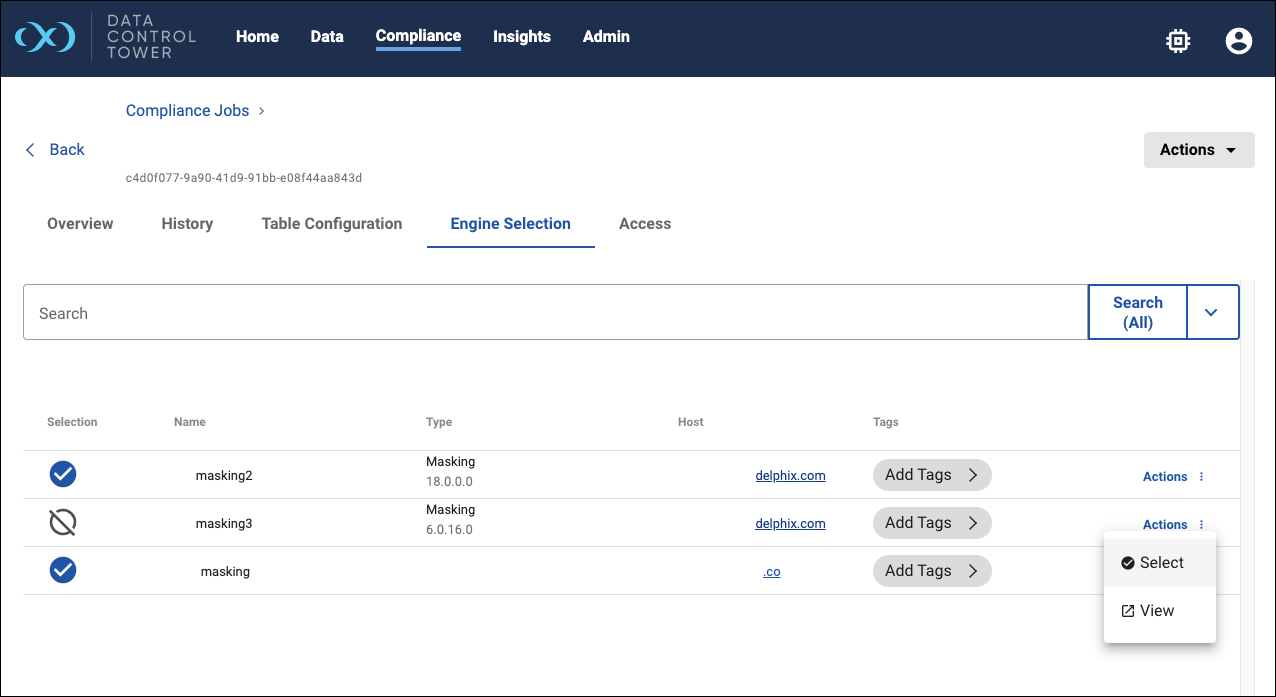
Hyperscale job engine selection
The Engine Selection tab allows you to manage the compliance engines that the job can use for masking. The table will list all compliance engines that are part of the Hyperscale Orchestrator’s engine pool. Each compliance engine will either be Selected or Not Selected for the job. The state of each engine is indicated by the Selection column and can be changed via the Actions menu.
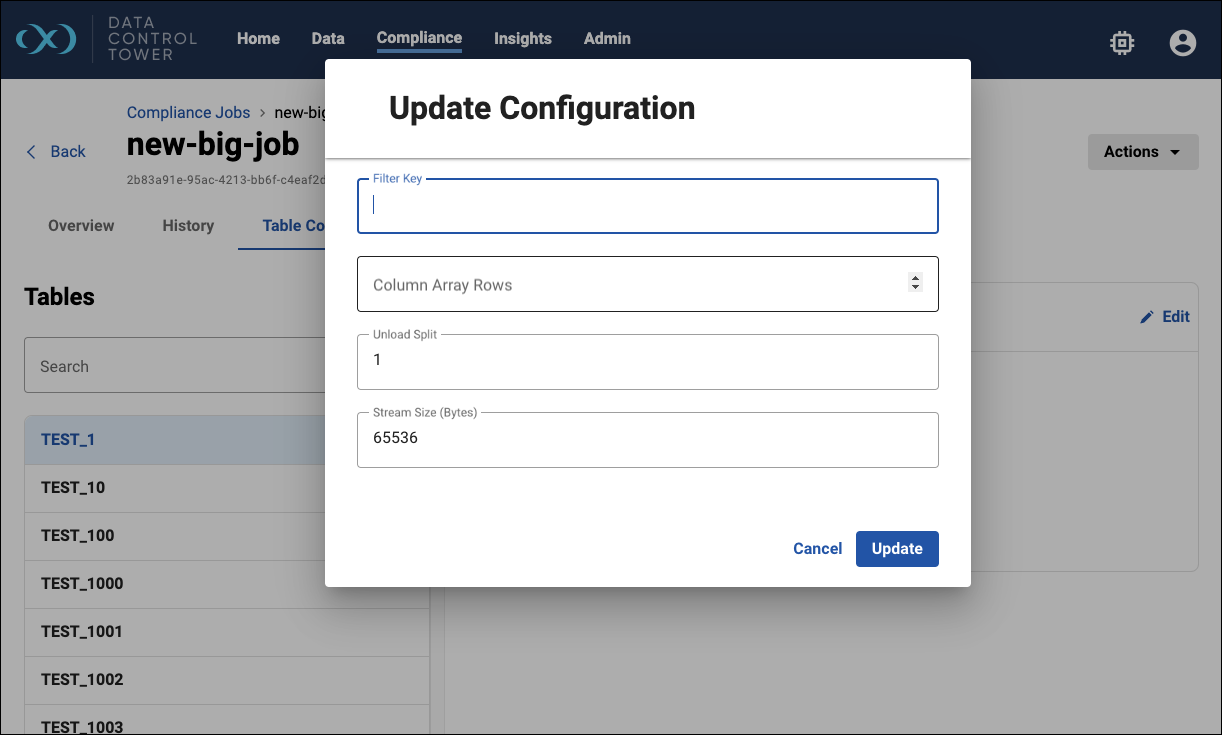
Hyperscale job table configuration
The Table Configuration tab contains the early stages of inventory management. You can see the Hyperscale dataset tables and their settings in the screenshot below. The left side shows the list of tables and allows you to search and paginate through the results.
The right side shows you the settings and allows you to make changes via the Edit action.
Executing Hyperscale jobs
A Hyperscale job can be executed via the Actions menu.
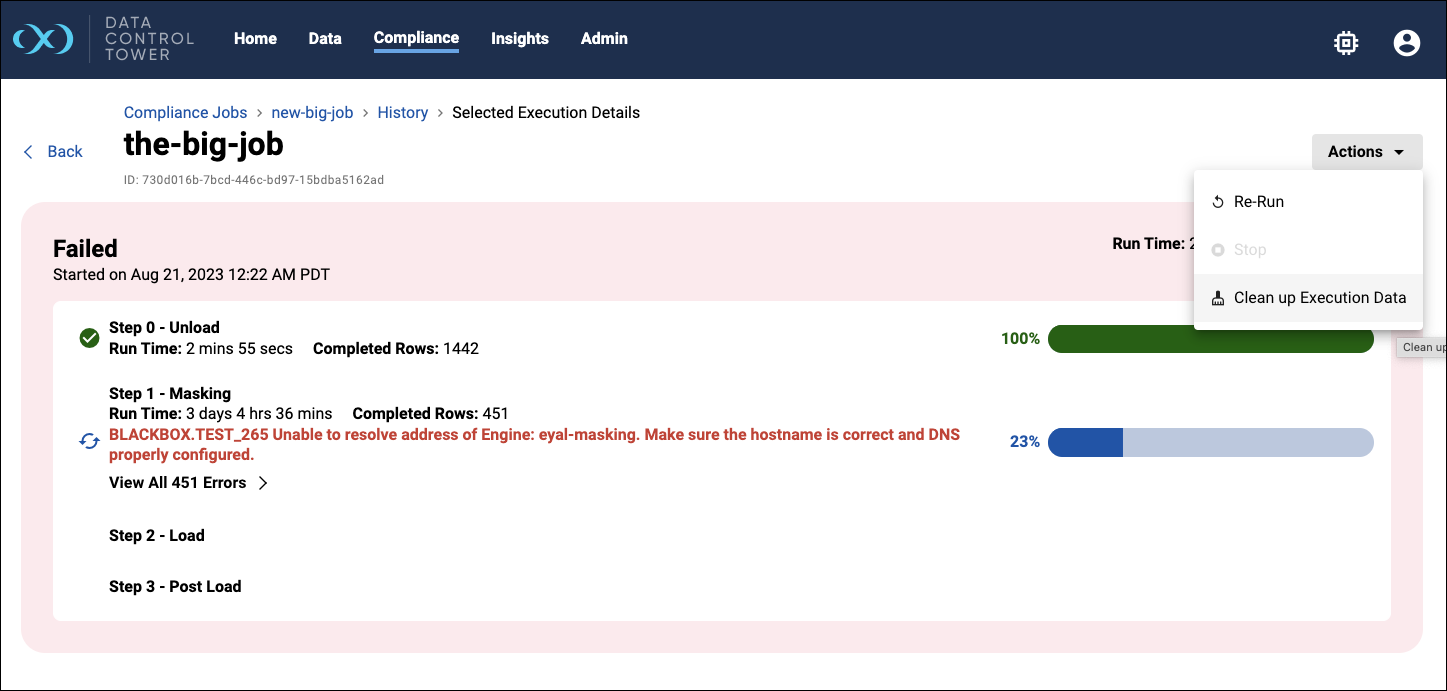
Once a job has started, a progress bar with details will appear in the Overview page.
Click the View Job Execution Details link to go to the Execution Details page to see job execution progress, as well as an Actions menu to Stop or Re-Run a job.
Details of a failed job will also be displayed in the Execution Details page. If the job was configured to retain execution data, the Clean option in the Actions menu can be used to discard this data.
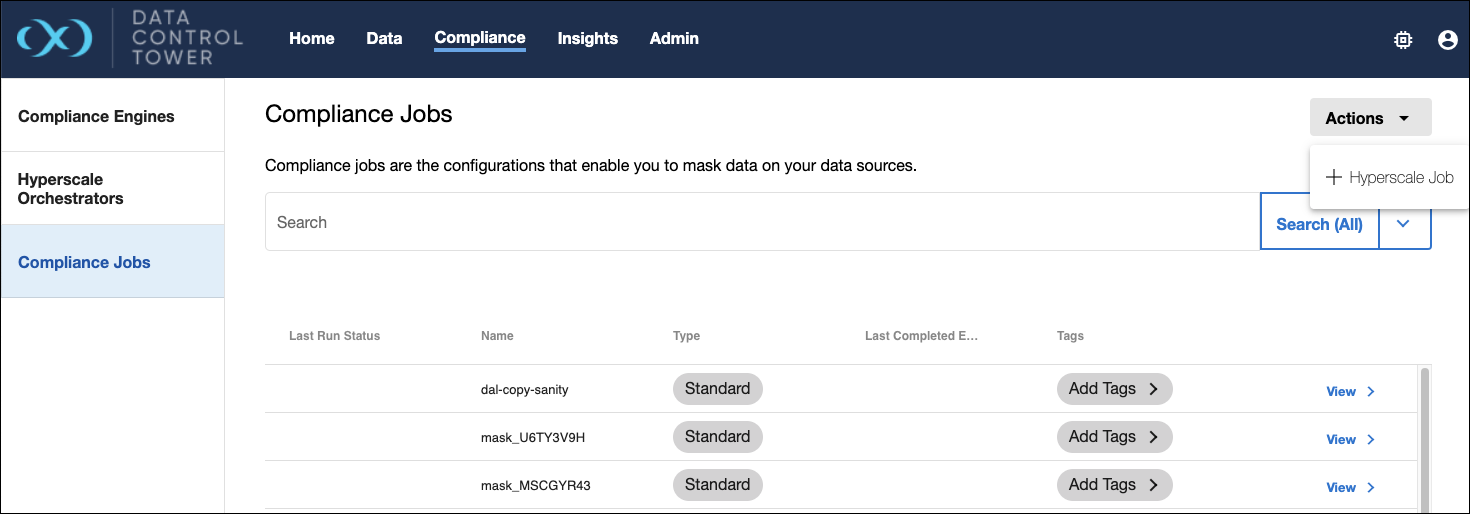
Creating Hyperscale jobs
New Hyperscale jobs can be created via DCT when you have a database compliance job setup on a Compliance Engine and need to use the same masking inventory in a Hyperscale job. DCT will export the masking job details from the Compliance Engine and import them into the Hyperscale Orchestrator. The result is a new set of Hyperscale connectors, a dataset, and a Hyperscale job.
Hyperscale job creation is currently only supported on Hyperscale Orchestrators of type ORACLE and MSSQL.
The + Hyperscale Job button in the Actions menu will initiate a wizard that walks you through the creation process.
After setting the new job name, description, and tags, the wizard will prompt you to select a source compliance job. This compliance job must be the source job on your compliance engine whose inventory you want to import. You must then explicitly select a Hyperscale Orchestrator to create the job on, along with the MountPoint to use. Finally, set any and all configuration settings that are relevant to the job you want to create.
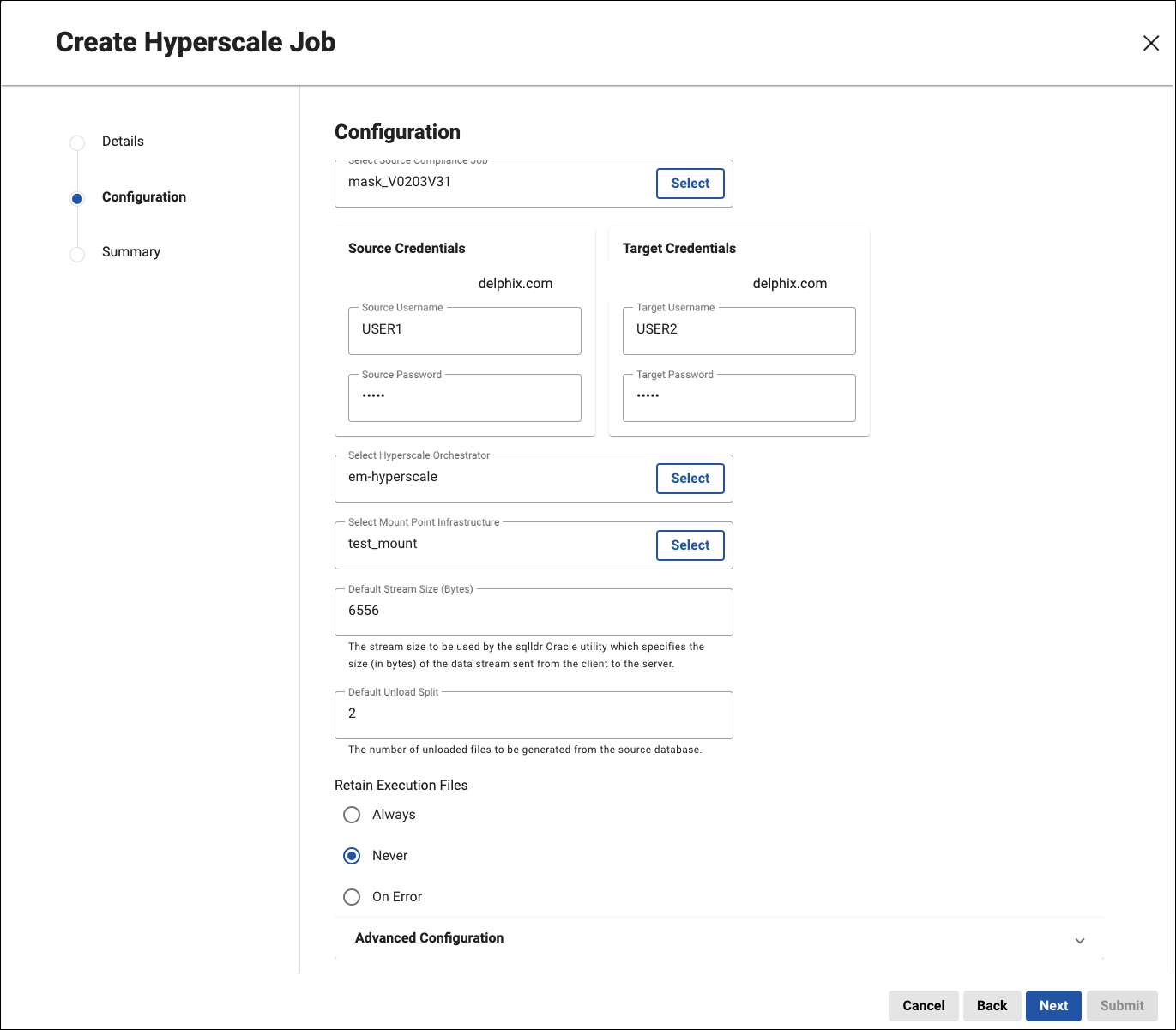
By default, DCT will create the Hyperscale job using all available Compliance Engines in the orchestrator’s pool. If changing this selection is required, it can be done after job creation in the Engine Selection tab of the job’s details page.
Currently DCT does not validate or enforce required input parameters. The requirements to create a Hyperscale job will differ depending on the Hyperscale Orchestrator version and database type.
As a reminder, the import process will not include any secure credentials for connectors. You have the option to set the connector credentials up front when creating the job (see screenshot above). Otherwise, you must independently find the imported connectors and explicitly set the credentials after the job has been created.
If your source compliance job is using any global objects such as Algorithms, those global objects must be pre-synced to all engines in the orchestrator’s engine pool. This can be done via the Manually Deploy Job Dependencies option in the Hyperscale Orchestrator’s Action menu.
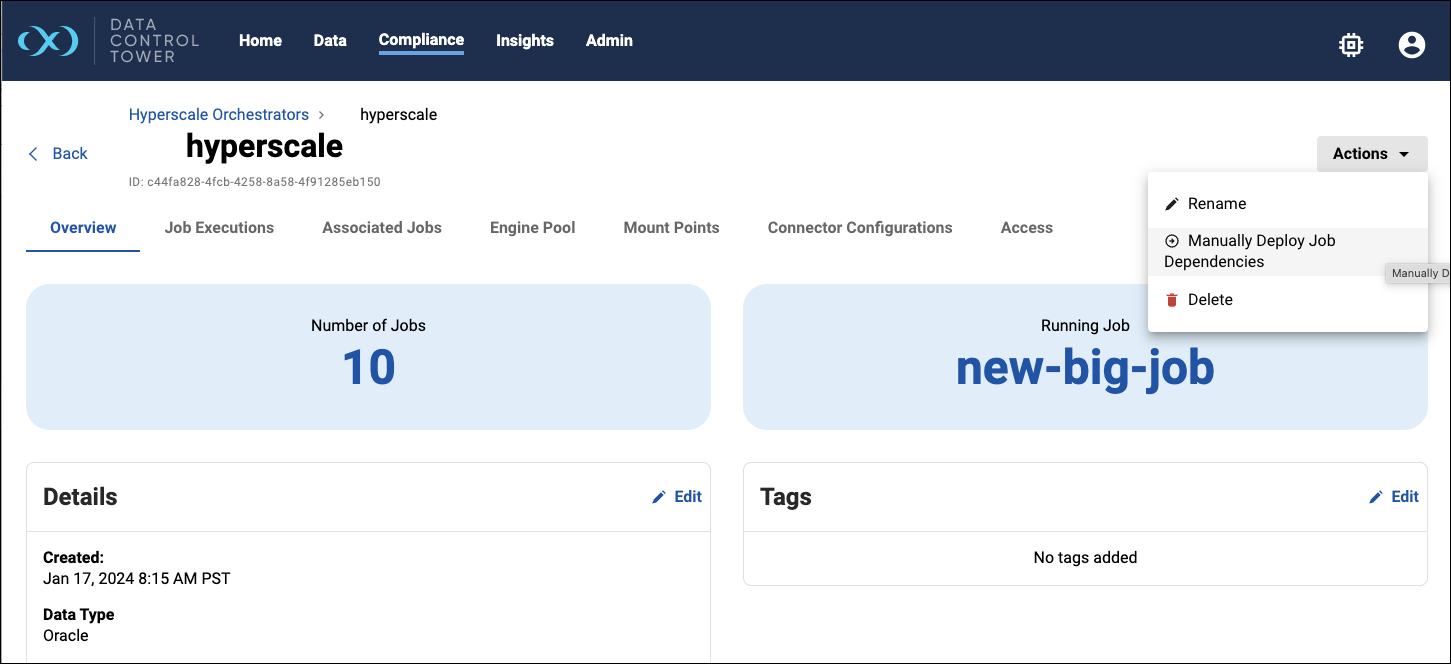
The wizard will walk you through the necessary steps which includes selecting the source compliance engine along with one or more target engines.
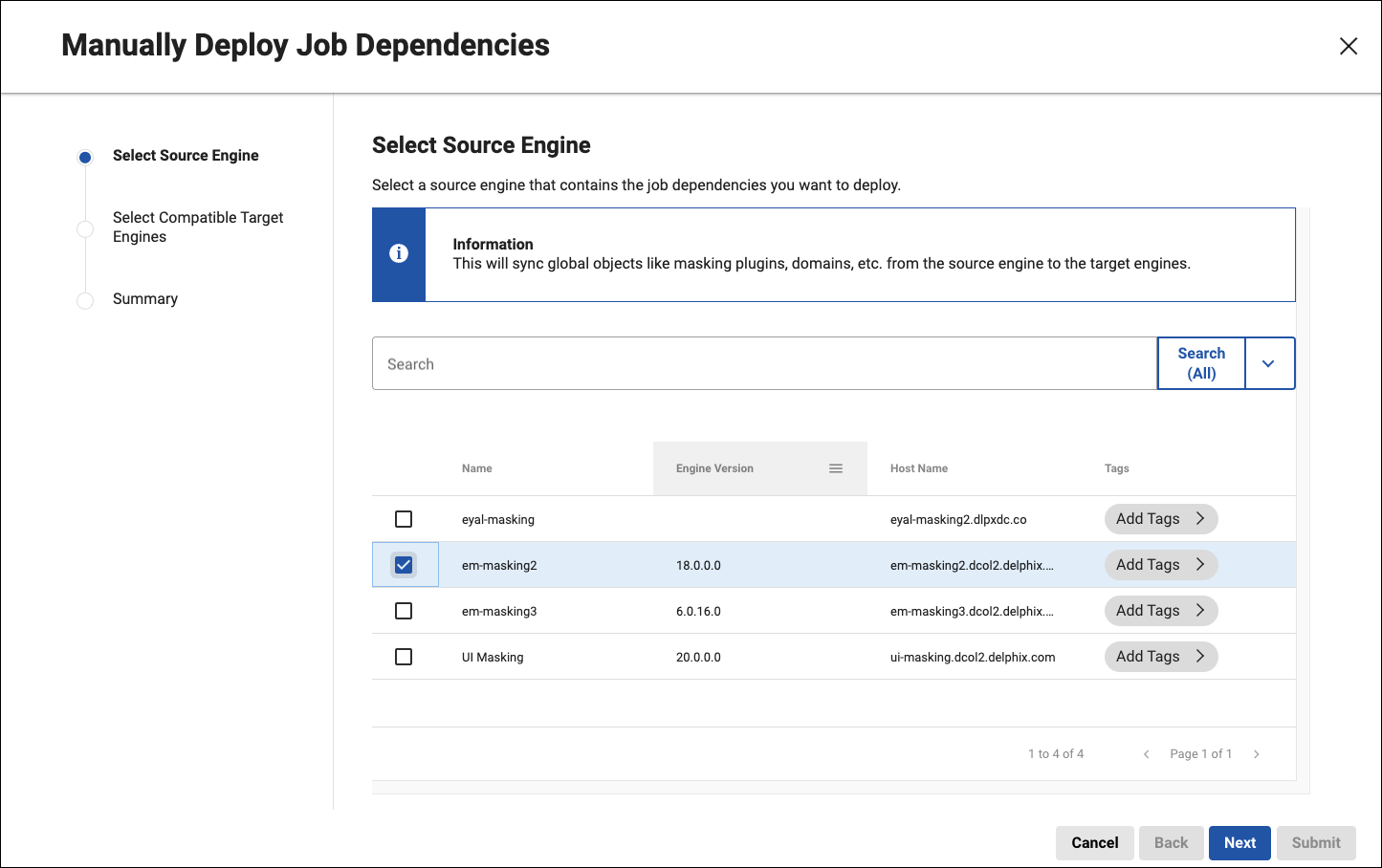
Please refer to the Hyperscale product documentation for the Hyperscale Orchestrator version you are running to learn all about the specifics of creating jobs in Hyperscale.
Updates to the original source compliance job can be done anytime after initial import and a re-import can be done via DCT. This will update the Hyperscale job’s existing dataset with the refreshed ruleset from the source compliance job.
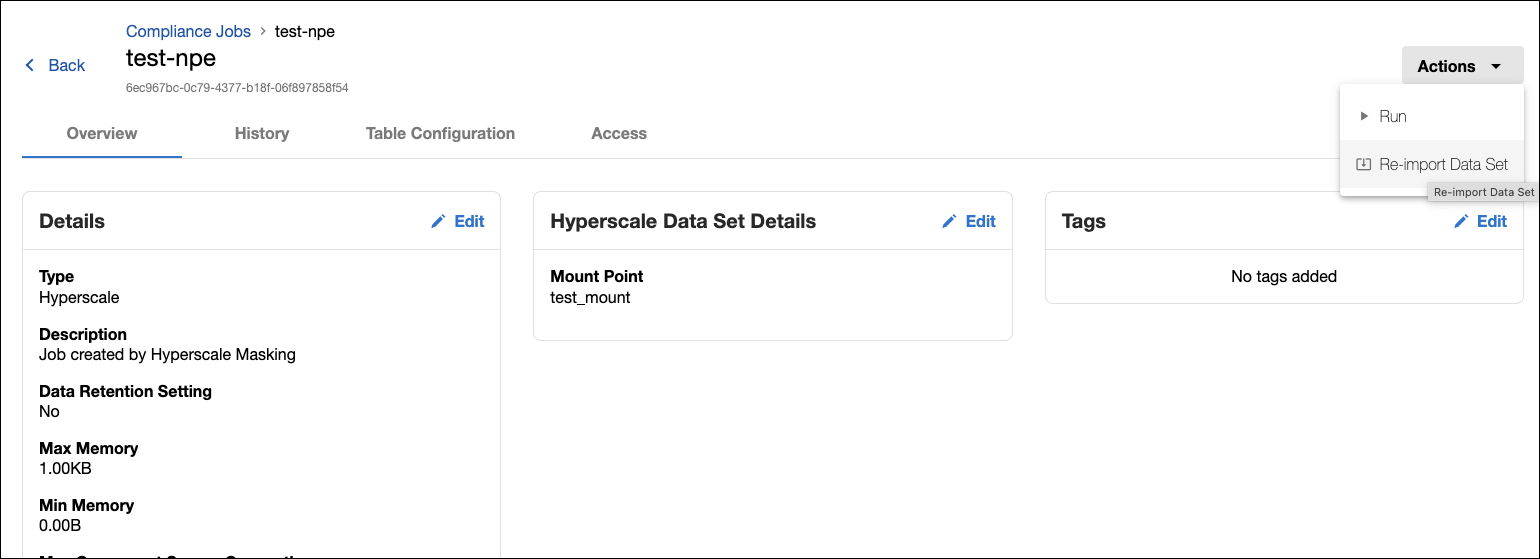
Note that this action will keep existing table configurations intact and the initial default settings for unload split and stream size will apply only to new tables. These settings can be changed for any table afterwards in the job’s Table Configuration details.
Hyperscale Compliance Engines
A view of all Compliance Engines registered with a Hyperscale Orchestrator can be found under the Engine Pool tab.
When DCT discovers the engines registered with a Hyperscale Orchestrator, it will create DCT RegisteredEngine entities out of them (if they do not already exist in DCT, as uniquely identified by the hostname). The result is a unified model where DCT RegisteredEngine objects are what make up the engine pool in a Hyperscale Orchestrator. The same engines will appear under the Compliance -> Compliance Engines page.
Engine credentials will not be retrieved from the Hyperscale Orchestrator, so the created engines must be updated with credentials, along with any relevant security settings. The discovered engines will remain in the OFFLINE status until updated.
The created DCT engine entities are permanent, in the sense that even if the origin Hyperscale Orchestrator is unregistered, the engines in DCT remain as if they had been registered independently of Hyperscale.
Adding new engines to the engine pool can be done by clicking the + Engine button. Only Compliance Engines that have already been registered with DCT can be added to a Hyperscale Orchestrator’s engine pool:
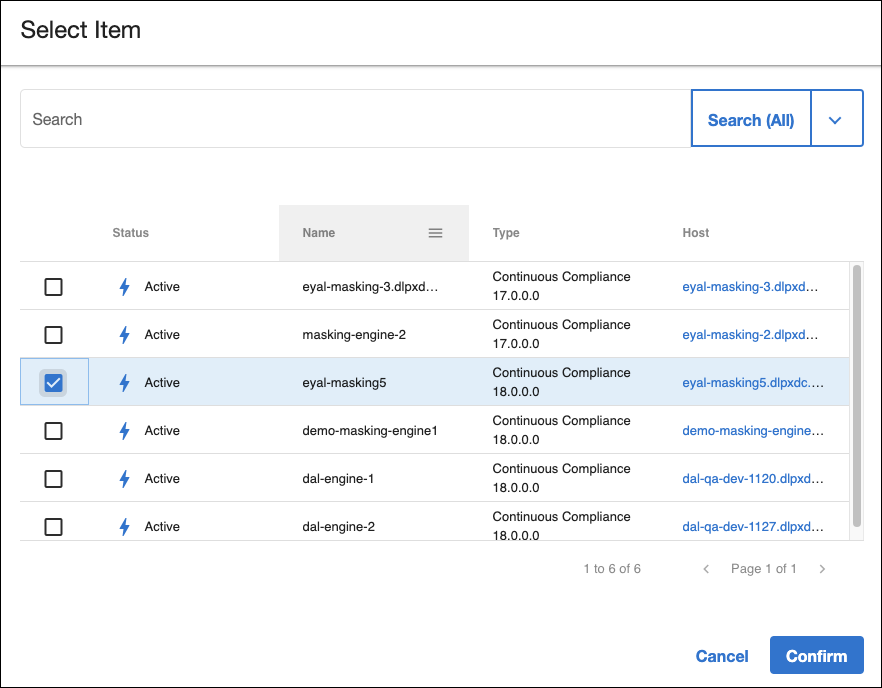
Note that this operation will, in turn, register the Compliance Engine with the Hyperscale Orchestrator. The Compliance Engine name, credentials, and configuration settings will be set according to DCT’s record.
Removing an engine from the engine pool can be initiated with the Remove button via the Actions menu:
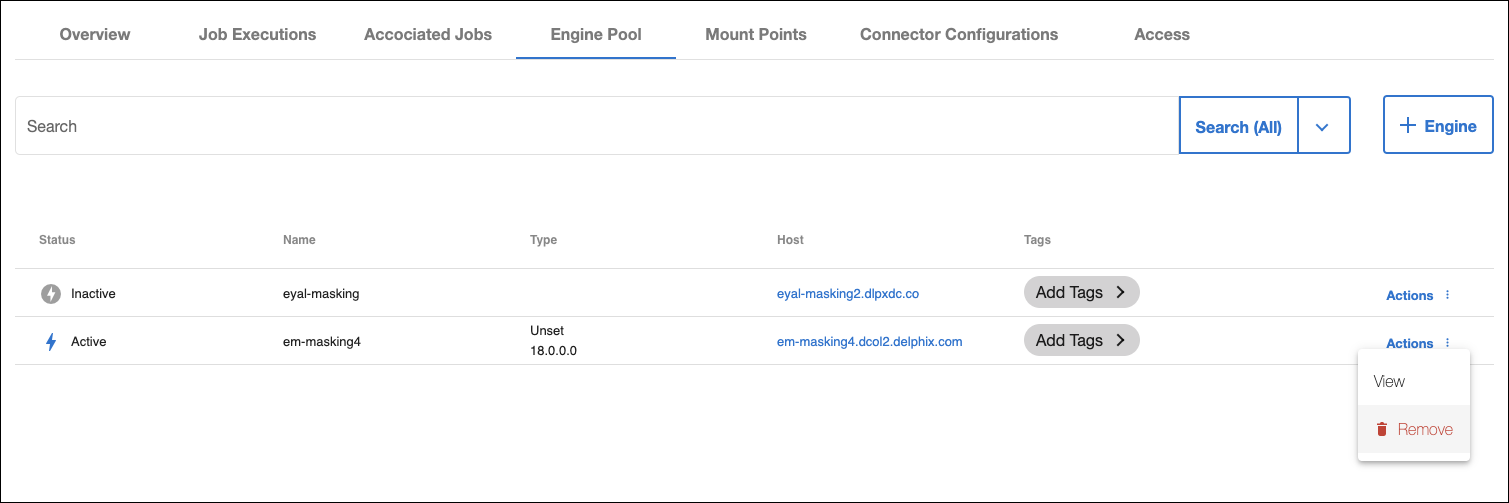
This will completely unregister the Compliance Engine from the Hyperscale Orchestrator.
Hyperscale mount points
A view of all mount points on a Hyperscale Orchestrator can be found under the Mount Points tab.
Creating new mount points can be done via the + Mount Point button.
This will result in a new mount point being created directly on the Hyperscale Orchestrator.
Editing and Deleting a mount point can be done for a particular row via the Action menu in the last column of the table.
Hyperscale connector configurations
A view of all connectors on a Hyperscale Orchestrator can be found under the Connector Configurations tab.
Creating new connectors can be done via the + Connector button.
Editing and Deleting a connector can be done for a particular row via the Actions menu in the last column of the table.